Migrating from Legacy Bedrock Agents to Strands Agents powered by Amazon Bedrock AgentCore Runtime

When AWS announced Amazon Bedrock AgentCore as the next evolution of their agent infrastructure, we knew it was time to take a hard look at our architecture. At
December 2025
When AWS announced Amazon Bedrock AgentCore as the next evolution of their agent infrastructure, we knew it was time to take a hard look at our architecture. At Hypertrail, we’d built our entire AI automation platform on Bedrock Agents, the only available solution when we started the platform. Now we had to figure out how to migrate. This blog post tells that story. It highlights the challenges we encountered, the solutions we found, and ultimately the value of our new runtime and how it positions Hypertrail perfectly for building the future of Agentic AI for the enterprise.
What We Were Working With
Hypertrail is a Context-first AI Agent platform. Our customers use it to build and deploy agentic Micro-use cases which are single-responsibility agentic use cases deployed for high-volume traffic powered by their Enterprise systems. In a nutshell, Hypertrail makes it easy for enterprises to connect Enterprise systems events in real time (think high volume booking, purchase, clickstream, employee records…) and trigger large parallel agentic use cases. We use a proprietary context storage layer allowing agents to access “digital twins” from their enterprise systems so that they always have the full business context needed to take the right action, for the right use case at the right time. Read more in our latest blog post.
For example, a retail brand can ingest real-time purchase events from their Point of Sales system, update the customer profile with the purchase and have agents generate and serve real-time personalized ads based on customer profile, purchase history and shopping mission intent.
To achieve this, customer create Micro-agents. Each customer creates dedicated micro-agents for each use case via our no-code interface. Behind the scenes, each agent maps to a Bedrock Agent that:
- Receives natural language prompts for each enterprise system event.
- Decides which tools to invoke (tools execution runs on AWS Lambda)
- Executes actions against customer systems and public tools
- Returns structured responses with full observability
The Hypertrail platform is primarily written in Go using the Amazon Bedrock Agent Go SDK. As we knew early on that we were building on early unproven tech that was likely to change quickly, we had the forethought to put Amazon Bedrock behind a clean interface (one of our best early design decisions). We will see later how this helped smooth the migration over.
type IAgentConfig interface {
CreateAgent(agentName, description, instructions, model string, options AgentOptions) (Agent, error)
DeleteAgent(agentId string) error
InvokeAgent(agent Agent, sessionID, memoryID, input string) (AgentResponse, error)
CreateApiActionGroup(agent Agent, name, description, schemaBucket, schemaPath, lambdaArn string) error
// ... 15+ methods
}
Why We Needed to Move
After re:Invent 2025, it had become clear that Amazon Bedrock AgentCore was where AWS was planning to concentrate most of their Agentic tooling investments. Announcements like A2A support, native MCP, Policies, native browser tools and many others made it clear that we were missing out on capabilities and needed to migrate fast.
AgentCore Runtime represents a significant shift in how AWS thinks about agents. Less managed, supports multiple open source frameworks like LangChain and Strands, it offers more flexibility and control at the expense of a more complex development experience.
What ChangedBedrock AgentsAgentCore RuntimeDeploymentLambda-backedECS-backedCustomizationConfigurationFull code control via open source frameworksTool ProtocolProprietaryMCP (Model Context Protocol)ObservabilityIn-stream tracesOpenTelemetry
Being new to AgentCore, we got started by asking Anthropic Claude Opus to analyze our architecture and recommend a migration path. The key recommendations:
- Use the Strands Agents SDK—a Python framework that runs natively on AgentCore. Opus suggested thta using langchain, while more feature-rich, might introduce unnecessary complexity compare to Strands.
- Use AgentCore Gateway for tool discovery via MCP. Note that, strangely, Opus did not recommend Gateway originally, we had to introduce the idea in the prompt.
- Keep the Go interface, but wrap the Python runtime behind it. Essentially, we use the AgentCore Go SDK to invoke the agent allowing us to stay compatible with the current implementation. The Strands Agent code itself is written in Python and running in a container executed by the AgentCore Runtime. (We prefer the AgentCore runtime to a standard container runtime like ECS because we assume AWS has and will further optimize it leading to lower run cost and more efficient implementation)
- Implement dual observability to maintain API compatibility. The current version of Hypertrail parses the agent traces at runtime and stores them directly in DynamoDB. AgentCore has been designed to support Open-Source observability standards and has a native AWS CloudWatch implementation. We will discuss later in this post why we chose to keep both our native DynamoDB trace storage and CloudWatch and how we ended up implementing.
We explicitly instructed Opus NOT to change anything and to start by creating a design document. After a little back and forth, Opus came up with this architecture that seemed sound.
┌─────────────────────────────────────────────────────────────────┐
│ Go Client (nm-core/strands/go) │
│ │
│ StrandsAgentConfig implements bedrock.IAgentConfig │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ bedrockagentcorecontrol (Control Plane) │ │
│ │ - CreateAgentRuntime (dynamic deployment) │ │
│ │ - UpdateAgentRuntime (update config) │ │
│ │ - DeleteAgentRuntime (cleanup) │ │
│ │ - ListAgentRuntimes │ │
│ └─────────────────────────────────────────────────────────┘ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ bedrockagentcore (Data Plane) │ │
│ │ - InvokeAgentRuntime │ │
│ └─────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────┐
│ Amazon Bedrock AgentCore Runtime (AWS Managed) │
│ │
│ • Serverless, auto-scaling │
│ • Session isolation (dedicated microVMs) │
│ • Built-in CloudWatch observability │
│ • Session persistence │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────────────────────────┐ │
│ │ Python Agent (Container on ECR) │ │
│ │ │ │
│ │ BedrockAgentCoreApp + Strands Agent │ │
│ │ - Configured via environment variables │ │
│ │ - Lambda tools │ │
│ │ - Knowledge base tool (OpenSearch) │ │
│ │ - Bedrock models │ │
│ └──────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
Directory Structure
Hypertrail is built on 3 main level of abstractions: 1/ At the top, we have functional use cases which include Hypertrail business logic directly triggered by API calls 2/ These business use cases share common logic via a nm-common package. 3/ All interactions with AWS services (including our legacy Amazon Bedrock implementation) are abstracted via an nm-core package. This has many benefits: It allows us to change implementations when AWS releases new services or non-backward compatible upgrades (the case of this blog post). It facilitates integration tests via advanced mocks. As a result we just needed to create a new implementation of our IAgentConfig interface in nm-core. This made the migration easy.
┌───────────────────────────────────────────────────────────────────────────┐
| Hypertrail Use Cases |
| (InvokAgent, Create Trail...) │
| ┌─────────────────────────────────────────────────────────────────┐ │
| │ Hypertrail Common │ │
| │ ┌─────────────────────────────────────────────────────────┐ │ │
| │ │ Hypertrail Core │ │ │
| │ └─────────────────────────────────────────────────────────┘ │ │
| └─────────────────────────────────────────────────────────────────┘ │
└───────────────────────────────────────────────────────────────────────────┘
Here is the code structure of our strand implementation
nm-core/strands/
├── go/ # Go client
│ ├── strands.go # StrandsAgentConfig implementation
│ ├── strands_types.go # Request/response types
│ ├── strands_mock.go # Mock for testing
│ ├── strands_test.go # Unit tests
│ └── strands_integration_test.go # Integration tests
│
├── agent/ # Python agent (for ECR deployment)
│ ├── agent.py # BedrockAgentCoreApp entrypoint
│ ├── tools/ # Tool definitions
│ │ ├── lambda_tool.py # Lambda action invocation
│ │ └── knowledge_base.py # OpenSearch RAG tool
│ ├── Dockerfile # ARM64 container
│ └── requirements.txt
│
├── deploy.sh # Deploy base container to ECR
├── deploy-local.sh # Run agent locally for testing
├── test.sh # Test runner
└── README.md # The readme file
Note that AWS offers a way to import existing Bedrock Agents into AgentCore but Hypertrail customers don’t use pre-configured agents. They create dedicated micro-agents through our platform at runtime. We needed to create agents programmatically, not import already created ones.
The Implementation
We started our AgentCore migration by implementing IAgentConfig for Strands.
// strands.go
type StrandsAgentConfig struct {
controlClient *bedrockagentcorecontrol.Client
dataClient *bedrockagentcore.Client
baseContainerURI string
runtimeRoleArn string
runtimeCache map[string]string
}
// static type check
var _ bedrock.IAgentConfig = &StrandsAgentConfig{}
With this in place, our existing backend code continued to work unchanged (plus-or-minus a few small non-backward compatible tweaks we had to make).
// This call works with BOTH implementations
responses, err := services.LlmService.CallAgents(
bedrock.Agent{ID: persona.AgentID},
requestedModels,
prompt,
sessionID,
sessionAttributes,
)
For this to work we had to create additional resources on AWS side that the Amazon bedrock implementation did not need. This includes:
- A new IAM role to be assumed by the AgentCore with the permissions to create/get the AgentCore runtime, Gateways. The calling compute (Lambda in our case) needs permission to pass this role to AgentCore. If you don’t provide the PassRole permission, you will get an undescriptive 403 error while calling your agent. This error comes all the way at the end when everything else is working which is rather frustrating
- An ECR Repository to store the agent container image.
- A test Lambda function to run integration tests with “real” actions. The Lambda function would support 2 tools: a Calculate tool and an Echo tool allowing us to verify that the agent is configured correctly and successfully calls the tools.
We created the following Test CDK stack to be able to fully run integration tests proving that our new implementation reproduces the exact same behavior as our legacy one.
export class StrandsTestInfraStack extends cdk.Stack {
constructor(scope: Construct, id: string, props?: cdk.StackProps) {
super(scope, id, props);
// ECR Repository for Strands Agent container
const ecrRepo = new ecr.Repository(this, 'StrandsAgentEcrRepo', {
imageScanOnPush: true,
removalPolicy: cdk.RemovalPolicy.DESTROY, // For test environment
lifecycleRules: [
{
maxImageCount: 10, // Keep last 10 images
},
],
});
// IAM Role for AgentCore Runtime
const agentCoreRuntimeRole = new iam.Role(this, 'AgentCoreRuntimeRole', {
description: 'IAM role for Strands AgentCore Runtime (dev)',
assumedBy: new iam.ServicePrincipal('bedrock-agentcore.amazonaws.com'),
managedPolicies: [
iam.ManagedPolicy.fromAwsManagedPolicyName('AmazonBedrockFullAccess'),
iam.ManagedPolicy.fromAwsManagedPolicyName('CloudWatchLogsFullAccess'),
iam.ManagedPolicy.fromAwsManagedPolicyName('AmazonEC2ContainerRegistryReadOnly'),
],
});
// Inline policy for Lambda invocation
agentCoreRuntimeRole.addToPolicy(
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: ['lambda:InvokeFunction'],
resources: [`arn:aws:lambda:${this.region}:${this.account}:function:*`],
})
);
agentCoreRuntimeRole.addToPolicy(
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: ['xray:PutTraceSegments'],
resources: [`*`],
})
);
// Permissions for AgentCore Gateway management
agentCoreRuntimeRole.addToPolicy(
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: [
'bedrock-agentcore:CreateGateway',
'bedrock-agentcore:GetGateway',
'bedrock-agentcore:DeleteGateway',
'bedrock-agentcore:ListGateways',
'bedrock-agentcore:UpdateGateway',
'bedrock-agentcore:CreateGatewayTarget',
'bedrock-agentcore:GetGatewayTarget',
'bedrock-agentcore:DeleteGatewayTarget',
'bedrock-agentcore:ListGatewayTargets',
'bedrock-agentcore:UpdateGatewayTarget',
],
resources: ['*'],
})
);
// Permissions for AgentCore Gateway invocation (MCP protocol)
// This allows the agent to connect to Gateways with IAM auth
agentCoreRuntimeRole.addToPolicy(
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: [
'bedrock-agentcore:InvokeGateway',
],
resources: ['*'],
})
);
// Additional permissions for Bedrock model invocation
agentCoreRuntimeRole.addToPolicy(
new iam.PolicyStatement({
effect: iam.Effect.ALLOW,
actions: [
'bedrock:InvokeModel',
'bedrock:InvokeModelWithResponseStream',
],
resources: ['*'],
})
);
// Test Lambda Function
// The Lambda code is in ../test_lambda/handler.py
const testLambda = new lambda.Function(this, 'TestLambda', {
runtime: lambda.Runtime.PYTHON_3_11,
handler: 'handler.lambda_handler',
code: lambda.Code.fromAsset(path.join(__dirname, '../../test_lambda')),
timeout: cdk.Duration.seconds(30),
memorySize: 128,
description: 'Test Lambda for Strands agent integration tests',
});
// CloudFormation Outputs
new cdk.CfnOutput(this, 'EcrRepositoryUri', {
value: ecrRepo.repositoryUri,
description: 'ECR repository URI for Strands agent container',
exportName: 'StrandsTestInfra-EcrRepositoryUri',
});
new cdk.CfnOutput(this, 'AgentCoreRuntimeRoleArn', {
value: agentCoreRuntimeRole.roleArn,
description: 'IAM role ARN for AgentCore Runtime',
exportName: 'StrandsTestInfra-AgentCoreRuntimeRoleArn',
});
new cdk.CfnOutput(this, 'TestLambdaArn', {
value: testLambda.functionArn,
description: 'ARN of the test Lambda function',
exportName: 'StrandsTestInfra-TestLambdaArn',
});
new cdk.CfnOutput(this, 'TestLambdaFunctionName', {
value: testLambda.functionName,
description: 'Name of the test Lambda function',
exportName: 'StrandsTestInfra-TestLambdaFunctionName',
});
}
}
The Python Side: Building the Agent Container
The Python agent runs inside a container image executed by the AgentCore runtime. AWS realized after implementing the first version of Bedrock, that the requirements to build an agent runtime platform was much closer to that of a standard compute service (microVM) than that of an LLM broker/API gateway. This is because the duration of agent use cases and their memory footprint varies greatly from one use case to another. As a result, the AgentCore runtime is essentially a new compute service specialized in running Agentic workloads. Our Python Agent needs to:
- Receive requests from the Go backend
- Connect to Gateway for tool discovery (we actually do this manually as the Strands documentation suggest auto-discovery is still in beta)
- Invoke the chosen LLM via Bedrock (and possible OpenAI/Gemini directly in the future).
- Execute tools through the MCP protocol
- Return responses along with necessary traces
Note that Hypertrail Agents are of a specific kind. They are triggered by real-time System events and execute actions autonomously which allows us to avoid some complexity by simplifying our Strands implementation. For example, we do not need things like streaming, agents do not interact back with the user…
Here’s the skeleton:
# agent.py
from bedrock_agentcore.runtime import BedrockAgentCoreApp, RequestContext
from strands import Agent
from strands.models.bedrock import BedrockModel
app = BedrockAgentCoreApp()
@app.entrypoint
def invoke(payload: Dict[str, Any], context: RequestContext) -> Dict[str, Any]:
prompt = payload["input"]["prompt"]
session_id = payload["input"]["session_id"]
session_attributes = payload["input"].get("session_attributes", {})
# Build and invoke the agent
result = invoke_with_gateway(prompt, session_attributes)
return {
"output": {
"message": result.message,
"traces": convert_spans_to_traces(),
},
"success": True,
}
Passing Session Attributes
We needed to pass session-specific context to our action Lambdas. Things like user IDs, organization IDs, custom headers. For the agent, these extra fields are unnecessary and likely to clutter the context (agent could prefer using information from the session over what the user instructed to do). So we wanted to pass this session context in a way that is transparent to the agent.
Luckily for us Strands lifecycle hooks allow us to intercept every tool call and inject data into the context. Here is a simplified implementation:
class SessionContextHook:
"""Transparently inject session context into tool calls."""
def __init__(self, session_attributes: Dict[str, Any]):
self.session_attributes = session_attributes
def register_hooks(self, registry, **kwargs):
from strands.hooks import BeforeToolCallEvent
registry.add_callback(BeforeToolCallEvent, self._wrap_tool_args)
def _wrap_tool_args(self, event):
tool_input = event.tool_use["input"]
tool_name = event.tool_use["name"]
# Extract action name (remove Gateway prefix)
action_name = tool_name.split("___")[-1]
# Add context without the agent knowing
tool_input["sessionAttributes"] = self.session_attributes
tool_input["action"] = action_name
When we create the agent, we pass this hook:
def invoke_with_gateway(prompt: str, tool_context: Dict[str, Any]):
mcp_client = create_mcp_client()
with mcp_client:
tools = mcp_client.list_tools_sync()
session_hook = SessionContextHook(session_attributes=tool_context)
agent = Agent(
model=BedrockModel(model_id=MODEL_ID),
tools=tools,
system_prompt=AGENT_INSTRUCTIONS,
hooks=[session_hook],
)
return agent(prompt)
Remains the problem of actually passing the session data to the Agent at invoke time. We initially tried to pass session attributes using Custom Headers. However we could not get this to work, so we pivoted to add session headers to the input payload
// InvokeInput contains the input parameters for agent invocation
type InvokeInput struct {
Prompt string `json:"prompt"`
SessionID string `json:"session_id"`
MemoryID string `json:"memory_id,omitempty"`
AgentID string `json:"agent_id,omitempty"`
ModelID string `json:"model_id,omitempty"`
SessionAttributes map[string]string `json:"session_attributes,omitempty"` // Custom attributes passed to agent
}
We then extract the attributes from the payload and only submit the prompt to the agent
# Extract session attributes from payload
tool_context = input_data.get("session_attributes", {}) or {}
if tool_context:
logger.info(f"Session attributes: {tool_context}")
prompt = input_data.get("prompt", "")
if not prompt:
return {
"output": {"message": "", "sources": [], "traces": []},
"success": False,
"error": "No prompt provided",
}
logger.info(f"Processing request: session={session_id}, prompt_length={len(prompt)}")
...
# Gateway requires MCP context management, can't cache agent
result = invoke_with_gateway(prompt, model_id, tool_context)
Next problem is passing the session attributes in the tool call without having every tool MCP server expose them (if not the agent would try to send them). This one was tricky. Our SessionContextHook does this. However, Hypertrail passes a flat map of action parameters at the root level. This means our MCP server definition will tell the agent to pass these parameters at the root of this object. This could lead to a messy structure where the payload received by our action executor has both the action parameters and metadata (like session attributes) at the root.
class SessionContextHook:
"""
Strands lifecycle hook that wraps tool arguments with session context.
This hook intercepts tool calls before they are sent to the Gateway/Lambda
and wraps the arguments with session attributes. The agent is unaware of
this wrapping - it happens transparently at the hook level.
See: https://strandsagents.com/latest/user-guide/concepts/hooks/
"""
def __init__(self, session_attributes: Dict[str, Any] = None):
self.session_attributes = session_attributes or {}
def register_hooks(self, registry: Any, **kwargs: Any) -> None:
"""Register hook callbacks with the Strands hook registry."""
from strands.hooks import BeforeToolCallEvent
registry.add_callback(BeforeToolCallEvent, self._wrap_tool_args)
logger.info("Registered BeforeToolCallEvent hook for session context wrapping")
def _wrap_tool_args(self, event: Any) -> None:
"""
Called before each tool invocation.
Adds session context to tool arguments.
The event.tool_use is a dict with "name" and "input" keys.
We add session_context and action to the input while preserving
the original parameters at the root level (required for Gateway schema validation).
"""
tool_name = event.tool_use["name"]
tool_input: Dict[str, Any] = event.tool_use["input"]
# Extract action name and id (split by ___)
# e.g., "test-lambda-tools___calculate_298792302394092730-928374" -> "calculate", "298792302394092730-928374"
action_id = tool_name.split("___")[-1] if "___" in tool_name else tool_name
# Add session context and action as extra keys
# Keep original params at root level for Gateway schema validation
tool_input["sessionAttributes"] = self.session_attributes
tool_input["action_id"] = action_id
logger.info(f"Added session context to tool '{tool_name}' (action: {action_id}): {tool_input}")
For a cleaner implementation we wanted to pass the action attributes in a nested object. We therefore updated the function that transforms our action definition into the Strands tool schema to add this. We do that in the Go code at gateway creation:
func toolDefinitionToStrand(toolDefs bedrock.ToolDefinition) types.ToolDefinition {
paramProperties := make(map[string]types.SchemaDefinition)
var paramRequired []string
for _, param := range toolDefs.Parameters {
schemaType := paramTypeToSchemaType(param.Type)
paramProperties[param.Name] = types.SchemaDefinition{
Type: schemaType,
Description: aws.String(param.Example), // Use example as description if no explicit description
}
paramRequired = append(paramRequired, param.Name)
}
// Wrap all parameters inside a "toolParameters" object
// This ensures the tool receives {"toolParameters": {"param1": value, ...}}
// instead of {"param1": value, ...} at the root level
return types.ToolDefinition{
Name: aws.String(toolDefs.ID),
Description: aws.String(toolDefs.Name + ": " + toolDefs.Description),
InputSchema: &types.SchemaDefinition{
Type: types.SchemaTypeObject,
Properties: map[string]types.SchemaDefinition{
"toolParameters": {
Type: types.SchemaTypeObject,
Properties: paramProperties,
Required: paramRequired,
Description: aws.String("Tool parameters"),
},
},
Required: []string{"toolParameters"},
},
}
}
As a result, the Hypertrail user configures
{
"key1": "value1",
"key2": "value2"
}
The agent is asked by the MCP server to send:
{
"toolParameters": {
"key1": "value1",
"key2": "value2",
},
}
And the Tool Executor received
{
"toolParameters": {
"operand1": 5,
"operand2": 3,
"operation": "multiply"
},
"action_id": "calculate",
"sessionAttributes": {
"userID": "XXXXXXXX",
"orgID": "XXXXXXX"
}
}
This solved it for us at no UX cost for the user.
SigV4 Authentication for Gateway
Next challenge. Our agent actions are executed via AWS Lambda this made the use of native IAM authentication for Gateway the best choice for us. After all one of the arguments Opus gave us to choose Strands was the AWS-native support. Using Cognito or OAuth would have added unnecessary complexity. We would have had to either create Cognito endpoints for every Action created by the user or every organization (Hypertrail follows a Multi-single tenancy model where the platform is multi-tenant but deploys dedicated cloud resources for each organization (more on that in this blog post)). Setting up IAM authentication was surprisingly harder than we would imagine given that Strands is built and supported by AWS.
The Strands SDK uses httpx for HTTP requests, which means we needed to implement SigV4 signing for httpx:
"""
Gateway Authentication for AgentCore Gateway MCP Tools
Provides AWS SigV4 authentication for Streamable HTTP MCP client
"""
import boto3
import httpx
from typing import Generator, Optional
from botocore.auth import SigV4Auth
from botocore.awsrequest import AWSRequest
from botocore.credentials import Credentials
class SigV4HTTPXAuth(httpx.Auth):
"""
HTTPX Auth class that signs requests with AWS SigV4.
Used for authenticating with AgentCore Gateway MCP protocol.
"""
def __init__(
self,
credentials: Optional[Credentials] = None,
service: str = "bedrock-agentcore",
region: Optional[str] = None,
):
"""
Initialize SigV4 authentication.
Args:
credentials: AWS credentials. If None, uses boto3 session credentials.
service: AWS service name (default: 'bedrock-agentcore')
region: AWS region. If None, uses default region from boto3 session.
"""
# Get credentials from boto3 session if not provided
if credentials is None:
session = boto3.Session()
credentials = session.get_credentials()
if credentials is None:
raise ValueError("No AWS credentials found. Configure AWS credentials.")
# Get region from boto3 session if not provided
if region is None:
session = boto3.Session()
region = session.region_name
if region is None:
raise ValueError("No AWS region found. Set AWS_REGION or configure AWS region.")
self.credentials = credentials
self.service = service
self.region = region
self.signer = SigV4Auth(credentials, service, region)
def auth_flow(
self, request: httpx.Request
) -> Generator[httpx.Request, httpx.Response, None]:
"""
Signs the request with SigV4 and adds the signature to the request headers.
This method is called by httpx for each request.
"""
# Create an AWS request
headers = dict(request.headers)
# Remove 'connection' header - it's not used in calculating the request
# signature on the server-side, and results in a signature mismatch if included
headers.pop("connection", None)
aws_request = AWSRequest(
method=request.method,
url=str(request.url),
data=request.content,
headers=headers,
)
# Sign the request with SigV4
self.signer.add_auth(aws_request)
# Add the signature header to the original request
request.headers.update(dict(aws_request.headers))
yield request
def get_sigv4_auth(
service: str = "bedrock-agentcore",
region: Optional[str] = None,
credentials: Optional[Credentials] = None,
) -> SigV4HTTPXAuth:
"""
Get a SigV4 auth handler for httpx requests.
Args:
service: AWS service name (default: 'bedrock-agentcore')
region: AWS region. If None, uses default region from boto3 session.
credentials: AWS credentials. If None, uses boto3 session credentials.
Returns:
SigV4HTTPXAuth instance for use with httpx clients and MCP streamablehttp_client
"""
return SigV4HTTPXAuth(
credentials=credentials,
service=service,
region=region,
)
def get_gateway_region_from_url(gateway_url: str) -> str:
"""
Extract AWS region from Gateway URL.
Gateway URLs follow pattern:
https://gateway-xxx.bedrock-agentcore.{region}.amazonaws.com/...
Args:
gateway_url: AgentCore Gateway URL
Returns:
AWS region (e.g., 'us-west-2')
"""
import re
# Pattern for extracting region from Gateway URL
pattern = r'bedrock-agentcore\.([a-z0-9-]+)\.amazonaws\.com'
match = re.search(pattern, gateway_url)
if match:
return match.group(1)
# If we can't extract region, use default from boto3
session = boto3.Session()
region = session.region_name
if region is None:
raise ValueError(
f"Cannot extract region from URL: {gateway_url}\n"
"Please set AWS_REGION environment variable or configure AWS region."
)
return region
This plugs into the MCP client:
def create_mcp_client():
from strands.tools.mcp import MCPClient
from mcp.client.streamable_http import streamablehttp_client
credentials = boto3.Session().get_credentials()
auth = SigV4HttpxAuth(credentials, os.environ.get("AWS_REGION", "us-east-1"))
return MCPClient(lambda: streamablehttp_client(GATEWAY_URL, auth=auth))
By the way, if you are thinking “I don’t need to understand any of this. Opus 4.5 can implement this for me in a heartbeat”. You may be in for a nasty surprise. We used AI extensively for every possible bit of that implementation (even the initial design). But the best coding model on the planet only gave us a 50% success rate in implementing what we needed. And most of the time the code was written in a way that we could never maintain it over time. So… yeah… lots of rework. This being said, without AI, the whole project would probably have taken twice as long.
The Observability Challenge
This was the most frustrating aspect of the migration. Legacy Bedrock Agents returned traces in-stream. We then parse these highly technical traces and extract the data that is useful to the user (initial prompt, thinking of the agent, tool requests and responses, final responses). Our UI shows these traces in real-time and in a very user-friendly way that even non-technical users can view and understand. This is critical given that, contrary to traditional software, agents are non-deterministic. You don’t know exactly what will happen when the agent gets invoked. As a result, tracing is no longer just used for debugging but also as a normal part of user interaction with agents. AgentCore uses OpenTelemetry and made the choice to export all traces to a software monitoring stack (for example CloudWatch). Traces in AgentCore are made for builders. They are highly technical. Structured in a recursive way that matches the structure of the agent loop, full of generated IDs, metadata, technical concepts (SPANS). Even the native AWS CloudWatch view is really meant for engineers. See for yourself the example of a simple tool call: 1 prompt, one tool, one agent.
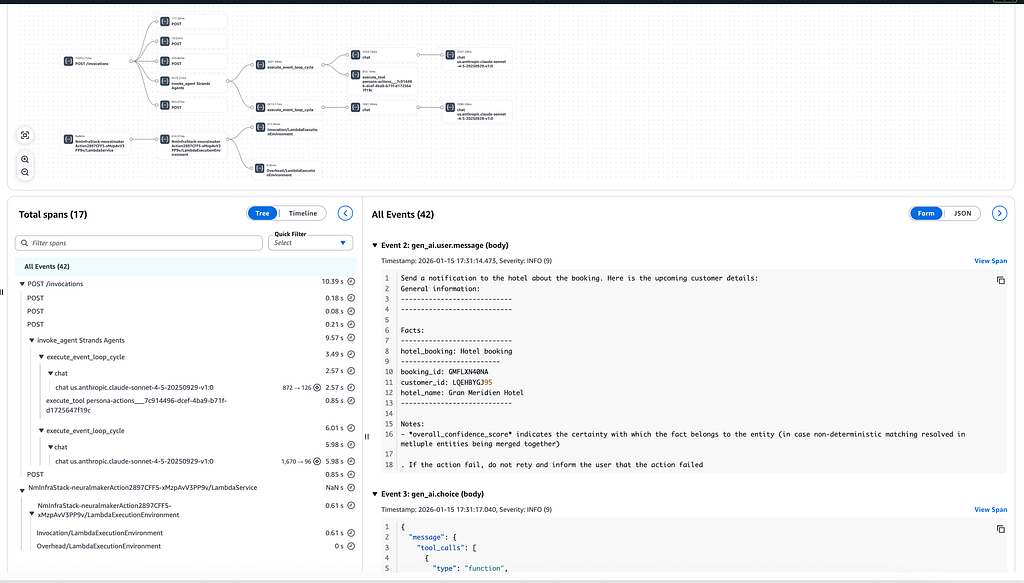
This is what traces look like in Hypertrail for a much more complicated use cases (3 tools executed sequentially to generated a dynamic Ad for a customer):


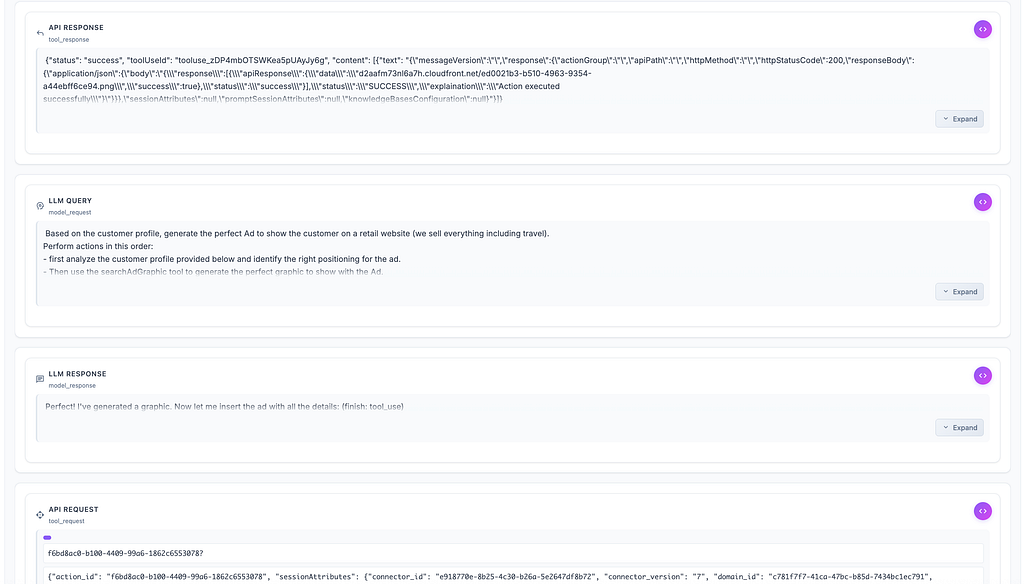
So we needed to access these detailed technical traces and map them to our existing schema. We tried several approaches:
- X-Ray API — We attempted to pass trace IDs and query X-Ray using the AWS SDK, but couldn’t get this to work. We tried passing traceId and parentTraceId to the AgentInvoke call and use this ID to get traces from X-Ray without success. We pivoted to using the CloudWatch API.
- CloudWatch Logs API — Similar attempt here. We could see the log group that had the agent traces in OTEL format. We even managed to query these logs but there was a significant lag between the agent execution and the logs availability in CloudWatch. Also, the polling logic was tricky. We could stop polling when CloudWatch stops returning logs but what if CloudWatch hasn’t received the last trace span? This approach, while possible, was complex and would likely not result in a great user experience. (Today, as soon as an agent gets called, users can use the trace ID and fetch the traces from DynamoDB in real time. Traces take a second or so to be ingested). So we pivoted again.
- Dual export — From the Strands documentation, we found out that you can add an in-memory exporter to the tracer provider to get access to the trace spans in real time in memory within the Python execution environment. This solved the trace access issue but we then needed to 1/ parse the traces and map them to our schema. 2/ make sure they contain the minimum data we need to power our trace view (initial prompt, thinking of the agent, tool requests with all params and responses, final responses).
We ended up doing something like that:
def convert_spans_to_traces() -> List[Dict[str, Any]]:
"""
Convert captured OpenTelemetry spans to AgentResponseTrace-compatible dicts.
Iterates through spans and their events, creating one trace per event.
Returns:
List of trace dicts matching AgentResponseTrace structure.
"""
from datetime import datetime
spans = get_captured_spans()
traces = []
for span in spans:
try:
trace_id_hex = format(span.context.trace_id, '032x')
span_id_hex = format(span.context.span_id, '016x')
parent_span_id_hex = format(span.parent.span_id, '016x') if span.parent else None
xray_trace_id = f"1-{trace_id_hex[:8]}-{trace_id_hex[8:]}"
span_events = getattr(span, 'events', []) or []
if len(span_events) == 0:
continue
# Loop through events within the span
for event in span_events:
try:
# Convert event timestamp (nanoseconds) to ISO timestamp
event_timestamp_ns = event.timestamp if hasattr(event, 'timestamp') else span.start_time if span.start_time else 0
event_timestamp_dt = datetime.utcfromtimestamp(event_timestamp_ns / 1e9)
event_timestamp_iso = event_timestamp_dt.isoformat() + "Z"
# Build raw event data for serialization
raw_event = {
"event_name": event.name if hasattr(event, 'name') else "unknown",
"event_timestamp_ns": event_timestamp_ns,
"event_attributes": dict(event.attributes) if hasattr(event, 'attributes') and event.attributes else {},
"span_name": span.name,
"span_id": span_id_hex,
"trace_id": xray_trace_id,
"parent_span_id": parent_span_id_hex,
}
# Build trace dict using event data
event_name = event.name if hasattr(event, 'name') else "unknown"
event_attrs = dict(event.attributes) if hasattr(event, 'attributes') and event.attributes else {}
# Initialize trace dict with defaults
trace_dict = {
"ID": xray_trace_id,
"Timestamp": event_timestamp_iso,
"raw": json.dumps(raw_event),
"TraceType": event_name,
"InputTokens": 0,
"OutputTokens": 0,
"actionGroup": "",
"apiPath": "",
"apiVerb": "",
"apiBody": "",
"apiParams": [],
"apiResponse": "",
"knowledgeBase": "",
"knowledgeBaseQuery": "",
"knowledgeBaseResponse": [],
"llmQuery": "",
"llmResponse": "",
"llmRepromptResponse": "",
"rationale": "",
"failureReason": "",
}
# Map event attributes to trace fields
# Tool-related events
if "tool.name" in event_attrs:
tool_name = str(event_attrs.get("tool.name", ""))
if "___" in tool_name:
trace_dict["actionGroup"] = tool_name.split("___")[0]
trace_dict["apiPath"] = tool_name.split("___")[1]
else:
trace_dict["actionGroup"] = tool_name
trace_dict["apiPath"] = tool_name
if "tool.input" in event_attrs:
trace_dict["apiBody"] = str(event_attrs.get("tool.input", ""))
if "tool.output" in event_attrs:
trace_dict["apiResponse"] = str(event_attrs.get("tool.output", ""))
# Agent prompt/response events
if "agent.prompt" in event_attrs:
trace_dict["llmQuery"] = str(event_attrs.get("agent.prompt", ""))
if "agent.response" in event_attrs:
trace_dict["llmResponse"] = str(event_attrs.get("agent.response", ""))
# Agent token counts (from accumulated usage)
if "agent.input_tokens" in event_attrs:
trace_dict["InputTokens"] = int(event_attrs.get("agent.input_tokens", 0))
if "agent.output_tokens" in event_attrs:
trace_dict["OutputTokens"] = int(event_attrs.get("agent.output_tokens", 0))
# Model request/response events
if "model.prompt" in event_attrs:
trace_dict["llmQuery"] = str(event_attrs.get("model.prompt", ""))
if "model.response" in event_attrs:
trace_dict["llmResponse"] = str(event_attrs.get("model.response", ""))
if "model.finish_reason" in event_attrs:
finish_reason = str(event_attrs.get("model.finish_reason", ""))
if trace_dict["llmResponse"]:
trace_dict["llmResponse"] = f"{trace_dict['llmResponse']} (finish: {finish_reason})"
else:
trace_dict["llmResponse"] = f"finish_reason: {finish_reason}"
if "model.input_tokens" in event_attrs:
trace_dict["InputTokens"] = int(event_attrs.get("model.input_tokens", 0))
if "model.output_tokens" in event_attrs:
trace_dict["OutputTokens"] = int(event_attrs.get("model.output_tokens", 0))
traces.append(trace_dict)
except Exception as e:
logger.warning(f"Error converting event to trace: {e}")
continue
except Exception as e:
logger.warning(f"Error converting span to trace: {e}")
continue
return traces
When mapping the data, we realized that a lot of fields we needed weren’t really accessible in the default trace. As mentioned before default traces are rather technical than functional. This was a problem, especially some missing fields like token counts which we use to bill our customers. There again, Hooks to the rescue. We implemented “tracing hooks” allowing us to intercept various events and enrich the traces with the data we need. This is what this looks like:
class TelemetryCaptureHook:
"""
Hooks into Strands execution to manually add OpenTelemetry Events to the current active span.
This captures key events like:
- Initial prompt (via BeforeInvocationEvent)
- Model requests (via BeforeModelCallEvent)
- Model responses (via AfterModelCallEvent)
- Tool requests (via BeforeToolCallEvent)
- Tool responses (via AfterToolCallEvent)
- Final response (via AfterInvocationEvent)
"""
def __init__(self):
"""Initialize the hook with storage for prompt."""
self._current_prompt = None
def _add_event_with_span_attrs(self, span: Any, name: str, attributes: Dict[str, Any]) -> None:
"""Add an event to the span, including all span attributes with 'span.' prefix."""
# Start with the event attributes
event_attrs = dict(attributes)
# Add all span attributes with "span." prefix
if hasattr(span, 'attributes') and span.attributes:
attrs = dict(span.attributes)
for key, value in attrs.items():
# Add each span attribute with "span." prefix
event_attrs[f"span.{key}"] = str(value)
span.add_event(name=name, attributes=event_attrs)
def register_hooks(self, registry: Any, **kwargs: Any) -> None:
"""Register hook callbacks with the Strands hook registry."""
try:
from strands.hooks import (
BeforeToolCallEvent,
AfterToolCallEvent,
BeforeInvocationEvent,
AfterInvocationEvent,
BeforeModelCallEvent,
AfterModelCallEvent,
)
registry.add_callback(BeforeInvocationEvent, self._on_invocation_start)
registry.add_callback(AfterInvocationEvent, self._on_invocation_end)
registry.add_callback(BeforeModelCallEvent, self._on_model_start)
registry.add_callback(AfterModelCallEvent, self._on_model_end)
registry.add_callback(BeforeToolCallEvent, self._on_tool_start)
registry.add_callback(AfterToolCallEvent, self._on_tool_end)
except ImportError:
# Fallback to tool hooks only if model hooks aren't available
try:
from strands.hooks import (
BeforeToolCallEvent,
AfterToolCallEvent,
)
registry.add_callback(BeforeToolCallEvent, self._on_tool_start)
registry.add_callback(AfterToolCallEvent, self._on_tool_end)
except ImportError:
pass
except Exception as e:
logger.warning(f"Error registering TelemetryCaptureHook: {e}")
def _on_invocation_start(self, event: Any) -> None:
"""Called before agent invocation starts - captures initial prompt."""
try:
current_span = trace.get_current_span()
if current_span.is_recording():
# Use stored prompt (set when agent is invoked)
prompt = self._current_prompt or ""
self._add_event_with_span_attrs(
current_span,
name="agent_prompt",
attributes={
"agent.prompt": prompt,
}
)
except Exception as e:
logger.error(f"Error in _on_invocation_start: {e}", exc_info=True)
self._add_event_with_span_attrs(
current_span,
name="agent_prompt",
attributes={
"trace_parsing_error": str(e),
}
)
def _on_invocation_end(self, event: Any) -> None:
"""Called after agent invocation completes - captures final response."""
try:
current_span = trace.get_current_span()
if current_span.is_recording():
# Extract response from event.agent.messages (per Strands docs: AgentData has state and messages)
response = ""
input_tokens = 0
output_tokens = 0
if hasattr(event, 'result'):
if hasattr(event.result, 'message'):
response = self._parse_message(event.result.message)
if hasattr(event.result, 'metrics') and hasattr(event.result.metrics, 'accumulated_usage'):
accumulated_usage = event.result.metrics.accumulated_usage
# Usage is a TypedDict, access as dictionary (per Strands docs)
input_tokens = accumulated_usage.get('inputTokens', 0)
output_tokens = accumulated_usage.get('outputTokens', 0)
self._add_event_with_span_attrs(
current_span,
name="agent_response",
attributes={
"agent.response": response,
"agent.input_tokens": input_tokens,
"agent.output_tokens": output_tokens,
}
)
except Exception as e:
logger.error(f"Error in _on_invocation_end: {e}", exc_info=True)
self._add_event_with_span_attrs(
current_span,
name="agent_response",
attributes={
"trace_parsing_error": str(e),
}
)
def _parse_message(self, message: Any) -> str:
"""Parse the message from the event.result.message."""
# Handle dict format: {'role': 'assistant', 'content': [{'text': '...'}]}
if isinstance(message, dict):
if 'content' in message:
content = message['content']
if isinstance(content, list):
for block in content:
if isinstance(block, dict) and 'text' in block:
return str(block['text'])
else:
return str(content)
else:
return str(message)
# Handle object format with content attribute
if hasattr(message, 'content'):
content = message.content
if isinstance(content, list):
for block in content:
if isinstance(block, dict) and 'text' in block:
return str(block['text'])
elif hasattr(block, 'text'):
return str(block.text)
# If no text found in blocks, join all blocks
return " ".join([str(block) for block in content])
else:
return str(content)
return str(message)
def _on_model_start(self, event: Any) -> None:
"""Called before model invocation - captures model request."""
try:
current_span = trace.get_current_span()
if current_span.is_recording():
# Get model name from span attributes (OpenTelemetry already captures this)
model_name = ""
if hasattr(current_span, 'attributes') and current_span.attributes:
attrs = dict(current_span.attributes)
if 'gen_ai.request.model' in attrs:
model_name = str(attrs['gen_ai.request.model'])
# Extract prompt from messages if available
prompt = ""
messages_count = 0
if hasattr(event, 'agent') and hasattr(event.agent, 'messages') and event.agent.messages:
messages_count = len(event.agent.messages)
# Get the last user message as the prompt
for msg in reversed(event.agent.messages):
if isinstance(msg, dict) and msg.get('role') == 'user':
content = msg.get('content', '')
if isinstance(content, list):
for block in content:
if isinstance(block, dict) and 'text' in block:
prompt = str(block['text'])
break
if prompt:
break
else:
prompt = str(content)
break
elif hasattr(msg, 'role') and getattr(msg, 'role', None) == 'user':
content = getattr(msg, 'content', '')
if isinstance(content, list):
for block in content:
if hasattr(block, 'text'):
prompt = str(block.text)
break
elif isinstance(block, dict) and 'text' in block:
prompt = str(block['text'])
break
if prompt:
break
else:
prompt = str(content)
break
self._add_event_with_span_attrs(
current_span,
name="model_request",
attributes={
"model.name": model_name,
"model.prompt": prompt,
"model.messages_count": messages_count,
}
)
except Exception as e:
logger.error(f"Error in _on_model_start: {e}", exc_info=True)
self._add_event_with_span_attrs(
current_span,
name="model_request",
attributes={
"trace_parsing_error": str(e),
}
)
def _on_model_end(self, event: Any) -> None:
"""Called after model invocation completes - captures model response."""
try:
current_span = trace.get_current_span()
if current_span.is_recording():
# Extract response from event.stopData (per Strands docs: ModelStopResponse has message and stopReason)
response = ""
finish_reason = ""
if hasattr(event, 'stop_response'):
stop_response = event.stop_response
# Extract message from stopData.message
if hasattr(stop_response, 'message'):
response = self._parse_message(stop_response.message)
if hasattr(stop_response, 'stop_reason'):
finish_reason = str(stop_response.stop_reason)
self._add_event_with_span_attrs(
current_span,
name="model_response",
attributes={
"model.response": response,
"model.finish_reason": finish_reason,
}
)
except Exception as e:
logger.error(f"Error in _on_model_end: {e}", exc_info=True)
self._add_event_with_span_attrs(
current_span,
name="model_response",
attributes={
"trace_parsing_error": str(e),
}
)
def _on_tool_start(self, event: Any) -> None:
"""Called before tool execution starts."""
try:
current_span = trace.get_current_span()
if current_span.is_recording():
tool_name = event.tool_use.get("name", "") if hasattr(event, 'tool_use') else ""
tool_input = event.tool_use.get("input", {}) if hasattr(event, 'tool_use') else {}
self._add_event_with_span_attrs(
current_span,
name="tool_request",
attributes={
"tool.name": tool_name,
"tool.input": json.dumps(tool_input) if tool_input else "",
}
)
except Exception as e:
logger.error(f"Error in _on_tool_start: {e}", exc_info=True)
self._add_event_with_span_attrs(
current_span,
name="tool_request",
attributes={
"trace_parsing_error": str(e),
}
)
def _on_tool_end(self, event: Any) -> None:
"""Called after tool execution completes."""
try:
current_span = trace.get_current_span()
if current_span.is_recording():
tool_result = json.dumps(event.result) if hasattr(event, 'result') else ""
self._add_event_with_span_attrs(
current_span,
name="tool_response",
attributes={
"tool.output": tool_result,
}
)
except Exception as e:
logger.error(f"Error in _on_tool_end: {e}", exc_info=True)
self._add_event_with_span_attrs(
current_span,
name="tool_response",
attributes={
"trace_parsing_error": str(e),
}
)
Note that these solutions aren’t perfect. There are still a few limitations in the Strands framework where some data is not accessible in certain hooks that produces some light degradation to our previous experience.
Overall things started working pretty well at this stage.
Testing It All
As mentioned earlier, we have a dedicated CDK stack to provision test infrastructure. This stack is deployed and updated in every pipeline as a prerequisite to running our integration tests. Our integration tests run the full flow:
- Deploy CDK stack
- Build and push the agent container
- Create an agent via the Go interface
- Add tools via Gateway
- Invoke the agent with prompts that require tool use
- Verify the responses and traces
- Clean up
We created dummy tools (a simple “echo” tool and a “calculate” tool) run in a dedicated Lambda to test the full agent loop including tool calling. A clever trick we found is to add a test that requires the agent to use information from the session attributes returned by the tool. For example “Calculate X+Y and add the bonus number from session attributes”. If the Agent returns the right number then it means that:
- The agent has been triggered
- The tool has actually been called (if not the bonus number would be unknown since only returned by the tool)
- The session attributes are passed correctly to the agents.
The last step was to make sure we support all the Large Language Models that Amazon Bedrock proposes. This is where we experienced our last and most significant issue but also where we unlocked an unexpected benefit.
Amazon Bedrock models support in AgentCore
At Hypertrail we follow an Iceberg methodology when it comes to testing. The functional code is the tip of the Iceberg but more of the codebase is composed of tests. We have an extensive test strategy starting with, of course, unit tests, integration tests, end-to-end tests, API and UI tests. We have a lot of AI tests as well. We test consistent response to standard prompts across all supported models. As a result our current test suite for the Legacy Bedrock Agent has a set of parallel tests that run a simple prompt to our agent framework across all supported models. When running these tests with our new Bedrock Agent Core implementation, we were surprised by a 25% success rate. These tests would only pass for Anthropic models.

We realized a fundamental difference between the way Amazon has implemented Bedrock Agents versus AgentCore. With Bedrock Agents, Amazon would propose a configurable system prompt that would tell Bedrock LLMs to structure the response within tags allowing Bedrock data plane to parse tool calling, knowledge base request instructions and execute it. This worked seamlessly with every model because every model has the capability to answer in unstructured text. As models have evolved over time AI labs have introduced a more structured request / response format. Tool call instructions for Anthropic models, for example, are returned in a dedicated “tool” section of the JSON response. The philosophy of implementation of Bedrock AgentCore with Strands is to delegate different use cases (tool calling, knowledge bases search…) to the capability of the underlying model. There is no longer an overlay that enforces a specific format on top of the model response. This approach is more future proof but requires a deeper understanding of each model’s capabilities and limitations. It also means that some models we were using would no longer be supported natively and that we would need to create custom model implementation in Strands if we wanted to continue to support them. This made us rethink our model support needs. After all, none of the enterprises we talked to at the end of 2025 really wanted DeepSeek, Llama or even Nova. But everyone would agree that support for Gemini, OpenAI and Anthropic should be table stakes. Unfortunately Bedrock Agent did not support OpenAI or Gemini (except for the OpenAI open-source model which had received mixed reviews). So this was never possible. Fortunately for us, Strands is an open-source framework. The way a model is supported in Strands is using an implementation of a ModelProvider. Bedrock-supported models have an existing BedrockModel but so do OpenAI and Gemini. All we had to do is to: obtain credentials for each of these model providers and use the already available ModelProvider similar to the example below from the Strands documentation
from strands import Agent
from strands.models.bedrock import BedrockModel
from strands.models.openai import OpenAIModel
# Use Bedrock
bedrock_model = BedrockModel(
model_id="anthropic.claude-sonnet-4-20250514-v1:0"
)
agent = Agent(model=bedrock_model)
response = agent("What can you help me with?")
# Alternatively, use OpenAI by just switching model provider
openai_model = OpenAIModel(
client_args={"api_key": "<KEY>"},
model_id="gpt-4o"
)
agent = Agent(model=openai_model)
response = agent("What can you help me with?")
A few learnings here too:
- We initially implemented OpenAI, Anthropic (via Bedrock), Gemini and Nova. However Nova kept failing with a strange error. This was unexpected given that Nova is Amazon’s own model. You would think it would work out of the box with minimal configuration. Turns out it doesn’t. We followed a couple tutorials but ultimately gave up given that, once again, most enterprises would choose between Anthropic, OpenAI and Gemini (unless it’s a Small Language Model (SLM) use case which we will eventually support).
- We had to deactivate streaming and set max_token to the max supported by the model.
# Extract parameters for BedrockModel
bedrock_params: Dict[str, Any] = {
"model_id": model_id,
"streaming": bedrock_config.get("streaming", False),
"max_tokens": bedrock_config.get("max_tokens", max_tokens),
}
- To this day we still run into an intermittent issue with Gemini Flash where the model attempts to run Python code instead of using the JSON syntax for tool calling if the tool is described as an email tool. (Our assumption is that because the model knows it can send email via Python runtime it chooses this and ignores our system prompt explicit request)
Overall we are pretty happy with the results:

Our platform now supports the 3 main Frontier models (Anthropic, OpenAI, Gemini) with a single implementation. Customers can test their business use cases across all these models and pick the cheapest model that passes their eval. And we are working on automating this so that across hundreds of thousands of Agent runs, we will always pick the cheapest model that has passed all evals set by the customer.
Conclusion and Notes on Agentic Coding
Overall, the migration was much harder than initially suggested when Opus 4.5 proposed the initial design. The first 50% were AI generated. We got to 80% fairly quickly (within a week or so) but the last 20% (traces parsing, new models support, overall integration into the platform) took much longer than expected and added 3 weeks to the project. At the end, 1 month for such a complex low level framework migration in a platform the size of Hypertrail with a production launch that has shown no critical regression so far is pretty acceptable. We were surprised by the lack of helpfulness of Agentic coding (we use Cursor and Claude Code with Opus 4.5 at the same time). The model is often able to give us a solution that works but most of the time we had to rework for maintainability or scrap the proposal because the model had adopted a tactical workaround instead of the long term solution we needed. Overall we are starting to think about our use of Agentic coding as driving a car: when you are on a tricky country road with lots of turns and blind spots, you don’t drive 70 miles an hour. You do that when you are on the highway with clear visibility ahead. Similarly with AI, if the ask is well structured, the AI is working within a well designed framework with plenty of examples to use as guidance, we switch over to Claude Code and just vibe-code the whole thing, have the AI create a pull request

However, when the implementation is a significant change to our platform where the Agent would likely update or delete significant chunks of existing code in critical or complex areas of the code base, we slow down, ask the agent to make a plan first. If the plan is good, we prompt one step at a time and test in between. If the plan is bad, we move to Cursor autocompletion and “surgical prompting” where we ask for small targeted changes in the code.
Overall our platform is now in such a stronger place than it was with Bedrock Agent. We rely on a modern open source agent framework (Strands). Our agents run on a dedicated fully managed runtime which AWS will monitor, operate and improve over time (instead of repurposing the Lambda runtime). We now support the most recent frontier models. We have native MCP support with Agent Gateway. This means that when customers create actions for their agents, we could eventually expose these actions via MCP not only to Hypertrail but to productivity AI tools outside of Hypertrail. Also Strands has support for features we haven’t explored yet (Browser tool, Guardrails, Native Evals, Memory, Policy Based Governance…). We are excited by the capabilities we will be able to add to the Hypertrail platform in 2026
Questions? Reach out to the engineering team at hypertrail.ai.